
1月4日,云顶平台网址国际工商云顶平台网址“管院讲坛系列学术讲座”第79期在线上召开。应我院邀请,上海财经大学信息管理与工程学院崔万云教授为我院师生分享了题为“基于知识图谱的问答技术:过去、现在和未来”的精彩讲座,邓莎莎副教授主持了此次会议。学院部分教授、教师、博士生、研究生及本科生参加了此次讲座。

崔万云,于2017年、2013年分别获得复旦大学博士、学士学位。研究兴趣是知识和语言的交叉。在NeurIPS、ICLR、SIGMOD、PVLDB、EMNLP、IJCAI和AAAI发表了多篇第一作者论文。
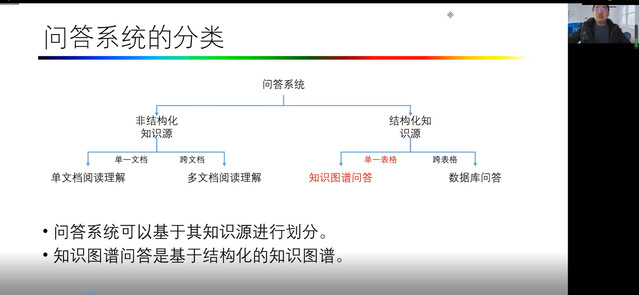
在本次讲座中,崔老师首先提出未来是以语言模型作为知识来源,通过语言和知识结合作为KBQI的未来。数据查询在面对海量数据、异质信息、语义理解与推理等新挑战,传统的数据搜索方式无法满足需要时,问答系统应运而生,回答提出的自然语言问题。问答系统可以给予知识来源进行划分,来自于非结构知识源和结构化知识源各有特点。今天的讲座关注于结构化知识源,其中单一表格体现的就是知识图谱问答。
知识图谱的特点首先是结构化、关联化的数据,每个节点表示一个实体,每一条边表示一条知识。通过这种不同类型的图谱联系不同实体,所体现出的就是知识图谱的表现形式。在真实的知识图谱中,表达的数据是非常大的,大概在千万级别,甚至可以上升到百亿级别,是一个非常庞大的知识库。
接着崔老师解答了为什么要使用知识图谱:一是KBQA可以为问题的语义理解提供丰富的背景知识。二是借由知识图谱,可以实现一些初步的推理能力,问答系统可以回答知识图谱没有直接表示的事实。因此,知识图谱是一种高质量、高效的问答方式。
崔老师再结合实例讲解了知识图谱的工作方式。其中SPARQL和SQL是针对知识图谱的一种专用的查询语言。其中的查询语言由数据库决定,但其中的核心问题是属性理解。为解决这个问题,过去采用了规则模板的方法,现在则是深度学习方法。规则模板的方法通过人工构造规则将问题映射到属性,可以达到较高的准确率,但是召回率较低;而深度学习方法将离散的问题表示为连续向量,通过深度神经网络理解问题,可以达到较高的准确率和找回率,但是神经网络的可解释性一般。事实上存在一些额外的方法,比如文本混合问答,可以将文本作为补充知识源,解决数据稀疏性问题,达到更高的准确率,但是使用条件更为严格,需要有配对的文本。之后,崔老师详细解释了规则模板的表现形式、方法以及优缺点。

随后,崔老师介绍了基于模板的问答过程的表现形式,解释用问题的概念替换它的实体的模板表示了问题的完整意图,关键在于如何收集大量模板并识别它们对应的属性。解决此问题的生成过程的方法是是Q2A,首先建立实体链接,然后做出概念化,在此基础上进行属性推断,从而进行值查找,整个过程就是一个概率图过程,目标是是学习所有数据的似然度。
基于刚才对于深度学习的介绍,崔老师进行了更为深度的解释和阐述,说明算法理解问题的过程,以及将知识图谱表示为离散特征的基本方式。
在形成知识图谱之后,基于知识问题的复杂程度,可以建立判别模型和生成模型的方式解决。其中简单意图的判别模型将问题理解转化为知识图谱属性识别的多分类问题,而复杂意图的表示则是生成模型的运用,运用强化学习的数据增强。使用深度学习方法可以将知识图谱表现为离散特征,通过向量化降维表示知识图谱语义。
崔老师重点关注的其实是对于知识图谱未来的发展的思考——语言模型作知识库的问答。预训练语言模型可以提升KBQA,将问题表示模型替换为语言模型。在原有的问答系统的分类上加入了参数化组织源,使用预训练语言。预训练语言的知识表达在于将知识图谱的关系转化为自然语言模板,并且通过语言模型查询。预训练模型还可以在特定模型条件下取得与知识图谱相似的效果。其他的一些方式则是通过融合语言模型和知识图谱做知识来源。基于各类语言和模型的特点,老师通过假设例子,提出如何建立接近真实世界的模型的问题,实现实体化的建构。
接下来崔老师总结了语言模型的特点,即提供了更高的覆盖率、更强的表达能力、更多上下文信息的知识源、支持知识推理。得出知识图谱与语言模型的融合是KBQA的未来的结论。
在问答环节中,老师和同学们积极提问,提出了关于多问题推理的相关问题,崔老师也结合自身研究进行了耐心细致的解答。随后,邓莎莎教授与崔老师交流了今后与管院线下交流与合作的事宜,本次讲座圆满结束。

